Lekce 1 - PostgreSQL - Úvod a příprava prostředí
Vítejte u prvního dílu seriálu tutoriálů k databázi PostgreSQL. Seriál je určen pro všechny, co se ještě s databázemi nesetkali a potřebují s nimi pracovat v dalším jazyce (např. v PHP na webu nebo v Javě v desktopové aplikaci). Smyslem je naučit vás základy jazyka SQL, které jsou podobné ve všech SQL databázích (PostgreSQL, MySQL, MS-SQL, SQLite...). Postupně si ukážeme vytváření tabulek, vkládání dat, jejich modifikaci a nakonec i výběr, vyhledávání a komplikovanější dotazy přes více tabulek.
Pracovat budeme pouze se samotnou databází a bez dalšího programovacího jazyka. Nebude to ale tak suché, jak to zní, protože budeme používat grafické rozhraní pgAdmin. Ukážeme si, jak věci naklikat (ty které jdou) a jak to samé zapsat i jako SQL dotaz. Z grafického rozhraní hezky pochopíte co přesně děláte a poté si to spojíte s SQL příkazem. Nabyté znalosti můžete využít v kterémkoli jazyce pro práci s PostgreSQL databází (např. v PHP či v Javě) a s minimální úpravou i s kteroukoli jinou SQL databází. Po dokončení tohoto seriálu budete schopni pracovat s databází na takové úrovni, abyste dokázali vytvořit jednoduchý redakční systém nebo podobnou aplikaci.
Relační databáze
PostgreSQL je tzv. relační databáze. Tento pojem označuje databázi založenou na tabulkách. Každá tabulka obsahuje položky jednoho typu. Můžeme mít tedy tabulku uzivatele, další tabulku clanky a další třeba komentare.
Databázovou tabulku si můžeme představit třeba jako tabulku v Excelu. Tabulka uzivatele by mohla vypadat asi takto:
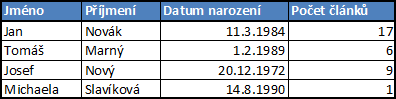
Položky (konkrétně zde uživatelé) ukládáme na jednotlivé řádky, sloupce pak označují atributy (vlastnosti, chcete-li), které položky mají. PostgreSQL databáze je typovaná, to znamená, že každý sloupec má pevně stanovený datový typ (číslo, znak, krátký text, dlouhý text...) a může obsahovat hodnoty jen tohoto typu. Pokud chceme s relační databází rozumně pracovat, každý řádek v tabulce by měl být opatřený unikátním identifikátorem. U uživatelů by to mohlo být třeba rodné číslo, mnohem častěji se však používají identifikátory umělé a to tak, že uživatele prostě očíslujeme. K tomu se dostaneme později.
Slovo relační označuje vztah (anglicky relation). Ten je mezi tabulkami nebo mezi entitami v jedné tabulce. To si ale necháme na jindy a zatím budeme pracovat jen s jednou tabulkou zároveň.
RDBMS
Možná vás napadlo, k čemu vlastně potřebujeme nějakou databázi. Data bychom stejně dobře mohli ukládat do nějakých textových souborů, binárek, XML nebo něčeho podobného. Určitě by to nějak fungovalo, nebo ne?
Označení databáze je vlastně nepřesné a v odborné literatuře se setkáme s označením RDBMS (Relation DataBase Management System). Česky je to přeloženo jako "systém řízení báze dat", což zní opravdu hrozně a proto budu dále používat označení databázový stroj nebo RDBMS. Databázový stroj (tedy zde PostgreSQL) není jen úložiště dat. Jedná se o velmi sofistikovaný a odladěný nástroj, který za nás řeší spoustu problémů a zároveň je extrémně jednoduchý k použití. S databází totiž komunikujeme jazykem SQL, kterým jsou v podstatě lidsky srozumitelné věty. Spolu s ukládáním dat je ale třeba dále řešit mnoho dalších věcí. Asi by nás napadlo např. zabezpečení nebo optimalizace výkonu. RDBMS toho ale dělá ještě mnohem více, řeší za nás problém současné editace stejné položky několika uživateli ve stejný okamžik, který by jinak mohl zapříčinit nekonzistenci databáze. RDBMS data v tomto případě zamkne a odemkne až po vykonání zápisu. Dále umožňuje spojovat několik dotazů do transakcí, kdy se série dotazů vykoná vždy celá nebo vůbec. Nestane se, že by se vykonala jen část. Tyto vlastnosti databázového stroje jsou shrnovány zkratkou ACID, pojďme si ji vysvětlit.
ACID
ACID je akronym slov Atomicity (nedělitelnost), Consistency (validita), Isolation (izolace) a Durability (trvanlivost). Jednotlivé složky mají následující význam:
- Atomicity - Operace v transakci se provedou jako jedna atomická (nedělitelná) operace. Tzn. že pokud nějaká část operace selže, vrátí se databáze do původního stavu a žádné části transakce nebudou provedeny. Reálný příklad je např. převod peněz na bankovním účtu. Pokud se nepodaří peníze odečíst z jednoho účtu, nebudou ani připsány na účet druhý. Jinak by byla databáze v nekonzistentním stavu. Pokud bychom si práci s daty řešili sami, mohlo by se nám toto velmi jednoduše stát.
- Consistency - Stav databáze po dokončení transakce je vždy konzistentní, tedy validní podle všech definovaných pravidel a omezení. Nikdy nenastane situace, že by se databáze nacházela v nekonzistentním stavu.
- Isolation - Operace jsou izolované a navzájem se neovlivňují. Pokud se sejde v jeden okamžik více dotazů na zápis do stejného řádku, jsou vykonávány postupně, jako ve frontě.
- Durability - Všechna zapsaná data jsou okamžitě zapsána na trvanlivá úložiště (na pevný disk), v případě výpadku el. energie nebo jiného přerušení provozu RDBMS vše zůstane tak, jak bylo těsně před výpadkem.
Databáze (přesněji databázový stroj) je tedy černá skříňka, se kterou naše aplikace komunikuje a do které ukládá veškerá data. Její použití je velmi jednoduché a je odladěna tak, jak bychom si sami zápis dat v programu asi těžko udělali. Vůbec se nemusíme starat o to, jak jsou data fyzicky uložena, s databází komunikujeme pomocí jednoduchého dotazovacího jazyka SQL, viz dále. V dnešní době se vůbec nevyplatí zatěžovat se otázkou ukládání dat, jednoduše sáhneme po hotové databázi, kterých je obrovský výběr a jsou většinou zadarmo. O databázi občas hovoříme jako o 3. vrstvě aplikace (1. vrstva je uživatelské rozhraní, 2. vlastní logika aplikace, 3. je právě datová vrstva).
Potřebné nástroje
Začněme tedy. Potřebovat budeme databázi PostgeSQL a pgAdmin, což je grafické uživatelské rozhraní pro administraci databáze.
Stažení PostgreSQL včetně pgAdmin: http://www.enterprisedb.com/…g/pgdownload
Instalace PostgreSQL je jednoduchá a uživatelsky přívětivá. Hlavně si zapamatujte heslo, které budete během instalace zadávat.
Spuštění installeru -> spustí se setup Microsoft Visual C++ 2013 (pokud nemáte nainstalováno). Následuje setup PostgreSQL -> nastavení Installation Directory -> Data Directory -> Password -> Port (defaultně 5432) -> Advanced Options - výběr locale -> Ready to Install. Dále se spustí Stack Builder 3.x.x pro instalaci dodatečného software. Zde není potřeba vybírat nic, vše potřebné je již nainstalováno.
Společně s PostgreSQL se nainstaloval i pgAdmin, což je grafické uživatelské rozhraní pro administraci databáze.
pgAdmin
pgAdmin je nejpoužívanější grafické prostředí pro práci s PostgreSQL databází. Otevřete si pgAdmin.

Dvojklikem na server se zobrazí okno pro zadání hesla (heslo jste zadávali v průběhu instalace).
Po úspěšném připojení je vám celá databáze (zatím máme jen jednu s názvem postgres, ale můžeme jich mít kolik chceme) k dispozici.
Základní pojmy
- schéma (schema) - Schémata jsou základní organizační jednotkou databáze. Pokud bychom si databázi představili jako stát, tak schémata by byly kraje. PostgreSQL automaticky při vytváření nové databáze vytváří schéma s názvem "public". Vše co vytvoříte umístí PostgreSQL do tohoto schéma, pokud mu neřeknete jinak. V rámci jednoduché databáze, která obsahuje pouze několik tabulek, je zcela v pořádku umístit vše do jednoho schéma. Pokud ale budete mít databázi se stovkami či tisíci tabulek, je určitě vhodné vytvořit více schémat a tabulky si zorganizovat.
- katalog (catalog) - Katalogy jsou systémová schémata. Jakékoliv informace o databázi a jejích objektech naleznete zde.
- role (role) - PostgreSQL používá role pro řízení přístupových práv k databázi. Roli si můžeme představit jako databázového uživatele (nebo jako skupinu uživatelů). Role, které se mohou přihlásit, se nazývají přihlašovací role (login roles). Role, které mohou obsahovat další role, se nazývají skupinové role (group roles). Když instalujete PostgreSQL, vytvoří se role postgres, pomocí které se můžete přihlásit.
Příště si vytvoříme svou první databázi a v ní i nějakou tabulku.
Lekce 2 - PostgreSQL - Vytvoření databáze a tabulky
V minulém dílu seriálu tutoriálů o PostgreSQL jsme si řekli něco o relačních databázích a připravili jsme si prostředí. Dnes si vytvoříme vlastní databázi a do ní nějakou tabulku.
Vytvořme si databázi. V pgAdmin klikněte pravým tlačítkem myši na Databases -> New Database….
Otevře se okno New Database, v něm vyplňte název nové databáze (Name) a potvrďte.


V databázích je zvykem pojmenovávat položky bez diakritiky, malými písmeny a s podtržítkovou notací. Snad vám je jasné, proč není diakritika dobrý nápad, za velkými a malými písmeny je Linux, který je rozlišuje a většina serverů právě na Linuxu běží.
Nyní máme vše připraveno k tomu, abychom se mohli začít učit jazyk SQL.
Jazyk SQL
SQL označuje Structured Query Language, tedy strukturovaný dotazovací jazyk. SQL je tzv. jazyk deklarativní. Zatímco u imperativních jazyků počítači vlastně říkáme krok po kroku co má udělat, u jazyků deklarativních pouze říkáme co má být výsledkem a již nás nezajímá, jak tohoto výsledku počítač dosáhne. Díky tomu jsou databázové dotazy zjednodušeny na příkaz typu "Vrať mi 10 uživatelů s nejvyšším hodnocením". Databáze takový dotaz pochopí, rozloží si ho na nějaké své instrukce a tak jej zpracuje. Nám poté opravdu vrátí výsledek, aniž bychom tušili, jak k němu došla. Pokud vám příkaz přišel jako nadsázka, tak tomu tak není a příkazy opravdu takto vypadají. Jen jsou anglicky.
SQL se původně jmenovalo SEQUEL (Structured English Query Language) a vzniklo v laboratořích společnosti IBM s cílem vytvořit jazyk, kterým by se dalo komunikovat s databází jednoduchou angličtinou. SQL (relační) databáze se poté rozšiřovaly a ujaly. Dnes se prakticky nic jiného nepoužívá a i když má SQL v objektovém programování značné nevýhody, firmám se nechce přecházet na nic jiného (i když existují alternativní řešení). Ale to jsme odbočili.
Naklikáním databáze nám pgAdmin vygeneroval a spustil příkaz v SQL, který vytvořil novou databázi. Tento SQL příkaz vypadá by asi takto:
CREATE DATABASE moje_databaze;
Přesnou verzi kódu, který byl použit pro vytvoření databáze můžete vidět, když kliknete v pgAdminu na databázi. V pravém dolním okně s názvem "SQL pane" uvidíte celý kód. Hodnoty jako encoding, tablespace, lc_collate atd. jsou použity defaultní a není potřeba se nyní jimi zabývat.
V SQL se většinou píší příkazy velkými písmeny, to proto, že je to lépe odliší od zbytku dotazu nebo od kódu naší aplikace (např. v PHP či Javě). Názvy tabulek, sloupců a další identifikátory jsou naopak malými písmeny a podtržítkovou notací.
Zkuste si databázi odstranit (kliknutí pravým tlačítkem myši na databázi, kterou chcete odstranit -> Delete/Drop -> potvrdit. Odstranit databázi se vám nemusí povést, pokud ji někdo používá (je do ní přihlášen).
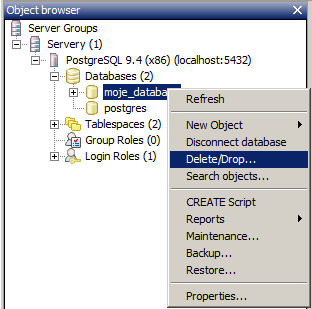
SQL příkaz pro smazání databáze je:
DROP DATABASE moje_databaze;
Už umíme 2 SQL příkazy, vytvoření databáze a její odstranění. Ani jeden ale v naší aplikaci asi používat nebudeme, protože databázi si stačí vytvořit jen jednou a můžeme to udělat takto jednoduše v administračním nástroji. To samé platí pro tvorbu tabulek. Teprve samotná práce s daty v SQL pro nás bude klíčová, brzy se k ní dostaneme.
Spuštění SQL dotazu
Nyní si databázi opět vytvoříme (viz postup výše). Označte myší nově vytvořenou databázi. V horní liště se vám zpřístupní tlačítko SQL.

Klikněte na něj a otevře se nové okno "Query" se záložkou "SQL Editor". Do horního levého okna je možné zadávat SQL příkazy a okně "Output pane" se zobrazí výsledek.

Nyní si vytvoříme tabulku. Vzpomeneme si na příklad tabulky uživatelů, co jsme si ukázali v minulém dílu. Měla sloupce jméno, příjmení, datum narození a počet článků. Již jsme nakousli, že by každá tabulka měla mít sloupec, jehož hodnota je pro každou položku unikátní. Sloupců bude tedy dohromady 5, tabulka se bude jmenovat "uzivatel". Zda budete při názvosloví tabulek používat jednotné či množné číslo záleží zcela na vás. Doporučuji ale být v tomto konzistentní. Pokud tabulky budete pojmenovávat v jednotném čísle, používejte to tak pro všechny tabulky. Pokud se rozhodnete pro množné číslo, platí to také. Hlavně nekombinujte oba způsoby. Tabulku je možné vyklikat i v pgAdmin.
Otevřeme okno pro vytvoření nové tabulky (moje_databaze -> Schemas -> public -> Tables -> pravým tlačítkem myši -> New Table). V záložce properties vyplníme název nové tabulky (Name).
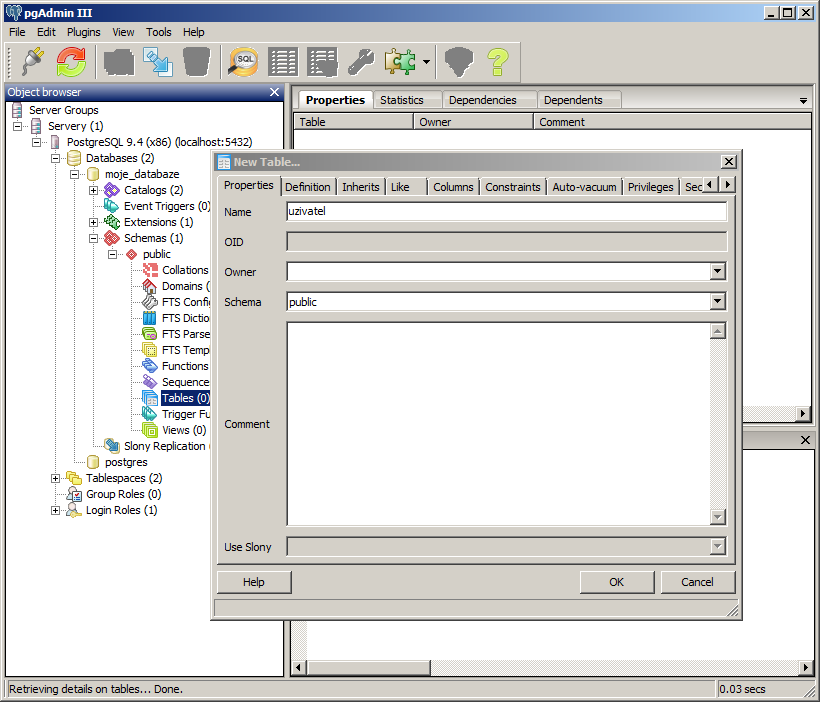
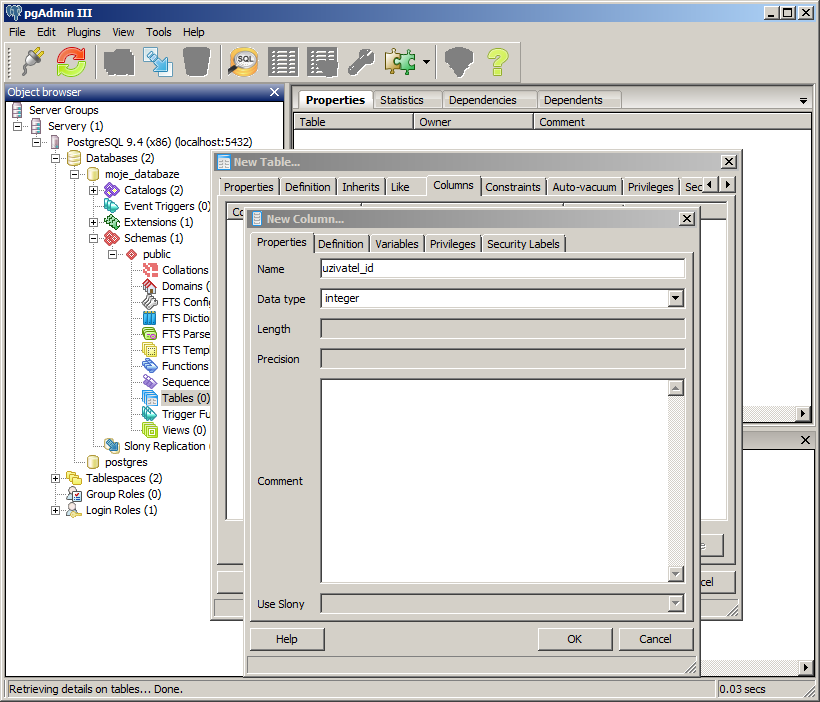
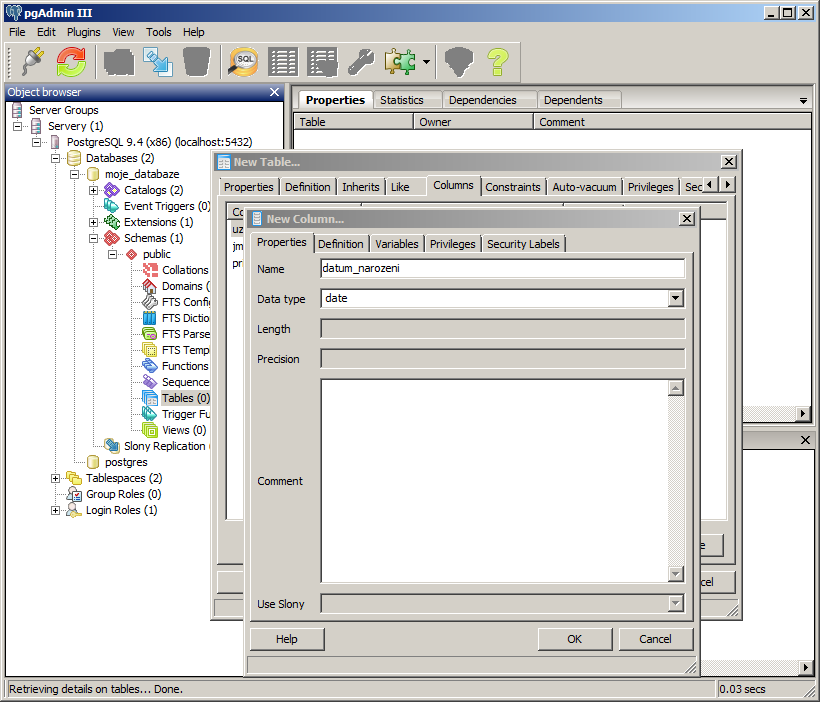
Přepneme se do záložky pro definování sloupců (Columns). Pomocí tlačítka přidat (Add) přidáme požadovaný počet a typ sloupců. Po kliknutí na tlačítko přidat (Add) se otevře nové okno s názvem New Column. Vyplníme název sloupce (Name) a datový typ (Data type). U určitých datových typů je třeba uvést i velikost daného datového typu (Length).
Datový typ představuje typ dat, který bude v daném sloupci uložen. Id záznamu (uzivatel_id) bude používat datový typ celé číslo (integer).
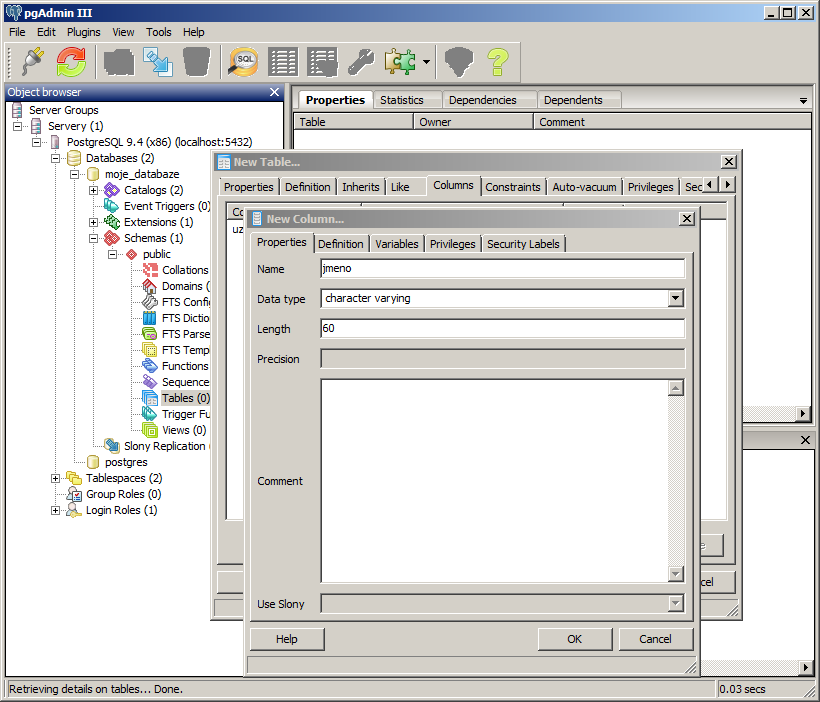
Sloupec pro jméno a příjmení bude datového typu textový řetězec (character varying). U tohoto datového typu je třeba uvést, jakou maximální délku řetězce (počet znaků) může daný text obsahovat. V našem případě nadefinujeme, že maximální délka řetězce bude 60 znaků. To by pro uložení jména nebo příjmení mělo stačit.
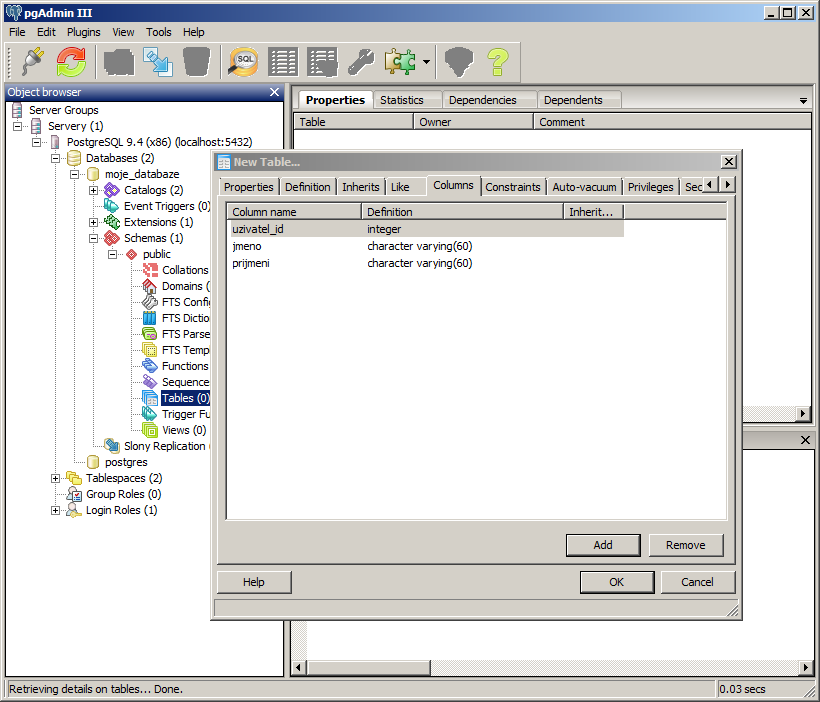
Sloupec pro uložení data narození bude datového typu date.
Počet článků bude opět používat datový typ integer (celé číslo).
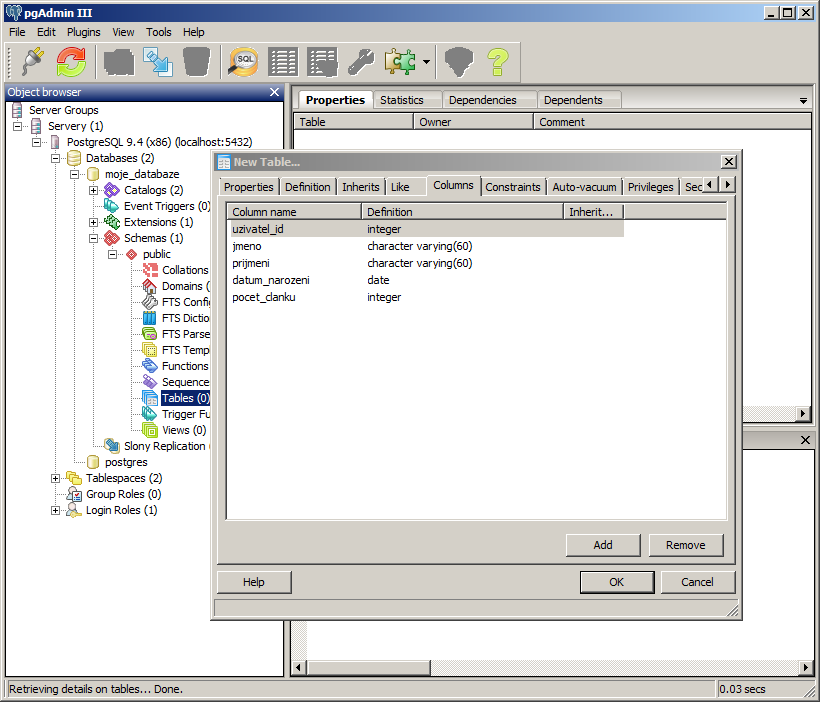
Sloupec uzivatel_id označíme jako primární klíč. To znamená, že databáze bude kontrolovat, zda se v tomto sloupci nenachází stejné hodnoty. Pokud bychom do tohoto sloupce chtěli vložit hodnotu, která se tu již nachází, dostali bychom chybu. Primární klíč je forma omezení (constraint), které se aplikuje na daný sloupec. Primární klíč znamená, že v daném sloupci se nachází jedinečné hodnoty. Primární klíč by měla mít každá tabulka (i když teoreticky nemusí). Když budeme chtít uživatele např. vymazat, vymažeme ho podle tohoto klíče (tedy podle uzivatele_id). Kdybychom ho mazali podle jména, smazali bychom několik položek, protože třeba Janů Nováků tam může být více. Podle uzivatele_id vymažeme vždy jen toho jednoho.
V pgAdmin primární klíč nastavíme tak, že se přepneme do záložky Constraints -> zvolíme Primary Key -> Add.
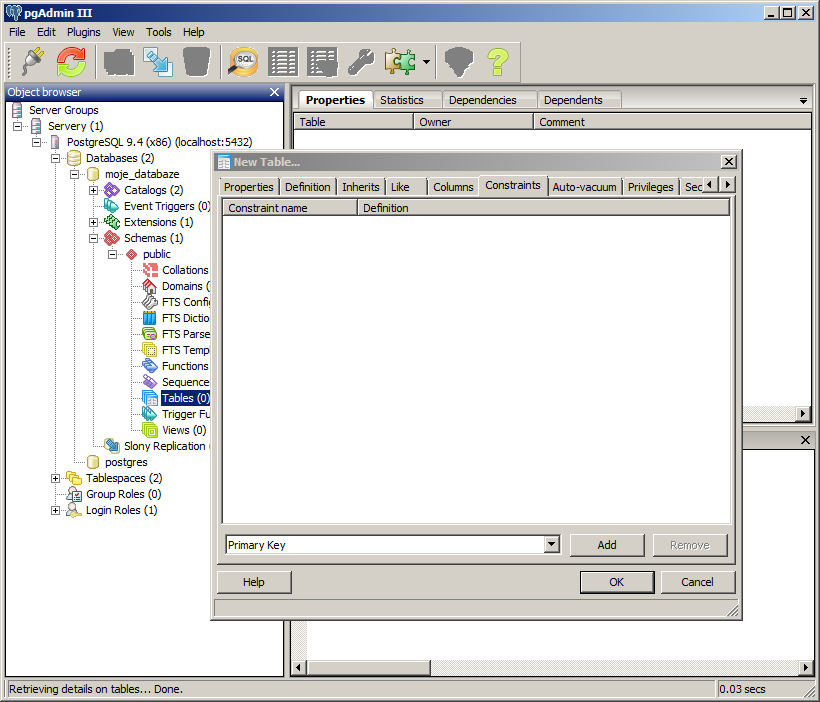
Otevře se okno New Primary Key, ve kterém vyplníme název. My si jej nazveme uzivatel_id_pk.
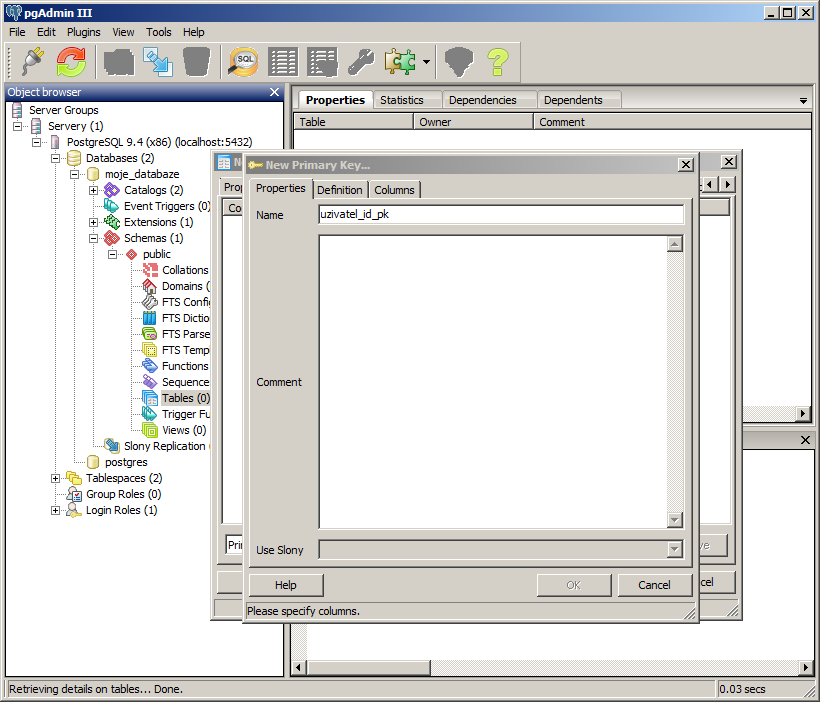
Nyní se přepneme na záložku Columns, kde určíme, na který sloupec tabulky se má tento primární klíč použít (vybereme sloupec a klikneme na Add).
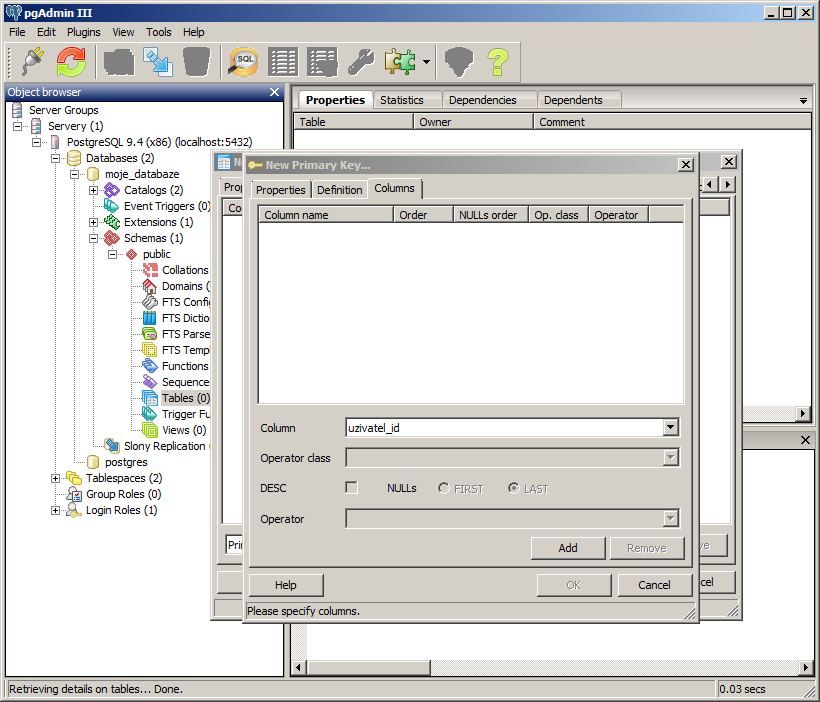
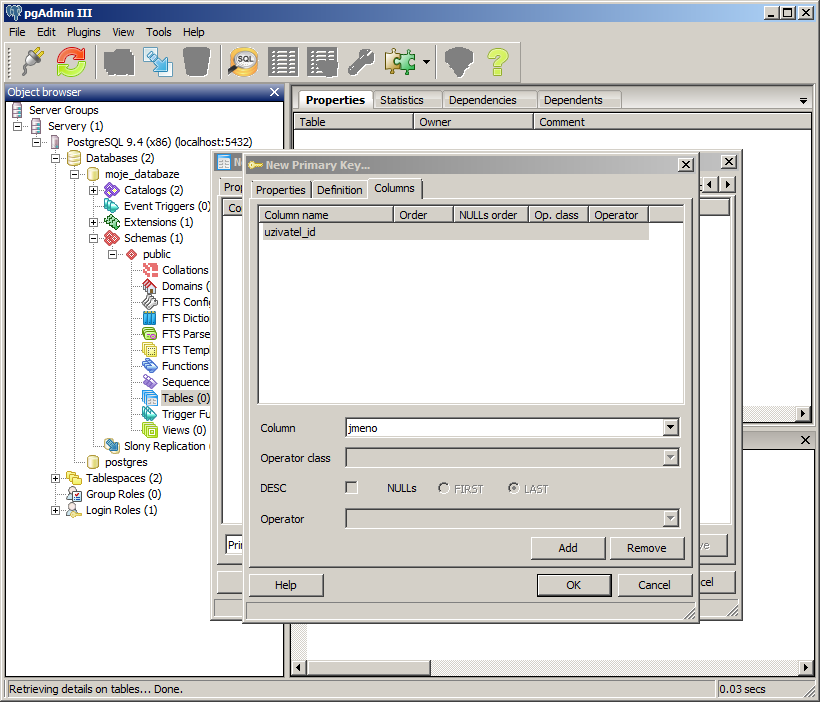
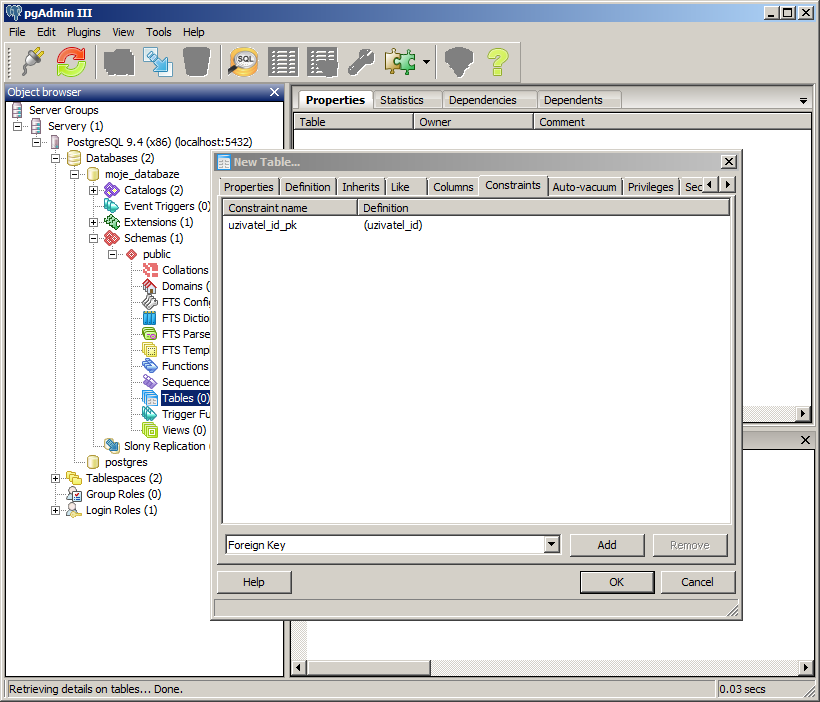
Pokud máme přidán primární klíč, potvrdíme vytvoření nové tabulky.

SQL příkaz pro vygenerování tabulky vypadá následovně.
CREATE TABLE uzivatel ( uzivatel_id integer NOT NULL, jmeno character varying(60), prijmeni character varying(60), datum_narozeni date, pocet_clanku integer, PRIMARY KEY (uzivatel_id) );
První řádek je jasný (příkaz pro vytvoření tabulky), na dalších řádcích se definují jednotlivé sloupce tabulky a jejich datový typ. U typu character varying uvedeme i počet znaků. Nakonec přidáme omezení (constraint) jako primární klíč na uzivatele_id.
Odstranění tabulky je stejné jako odstranění databáze. V pgAdmin ji odstraníte kliknutím pravým tlačítkem na tabulku a zvolením Delete/Drop.
V SQL by byl příkaz následující.
DROP TABLE uzivatel;
SQL příkaz pro vytvoření tabulky uzivatel lehce vylepšíme. U sloupce uzivatel_id používáme datový typ integer. To je naprosto v pořádku, ale vzhledem k tomu, že tento sloupec bude sloužit pouze jako identifikátor záznamů, můžeme použít datový typ serial. Serial není skutečný datový typ, ale ulehčení, které PostgreSQL nabízí. V případě, že uvedeme serial, se vytvoří sloupec s datovým typem integer, který bude automaticky při vložení záznamu do tohoto sloupce vkládat hodnotu, a tato hodnota se bude automaticky navyšovat. Nový SQL příkaz pro vytvoření tabulky je následující.
CREATE TABLE uzivatel ( uzivatel_id serial, jmeno character varying(60), prijmeni character varying(60), datum_narozeni date, pocet_clanku integer, PRIMARY KEY (uzivatel_id) );
Nyní si zkuste tabulku dropnout a poté znovu vložit pomocí SQL příkazu. Klikněte na tlačítko SQL, které vám otevře SQL Editor. Do horního levého okna vložte váš SQL příkaz a klikněte na tlačítko Execute query (zelená šipka play).
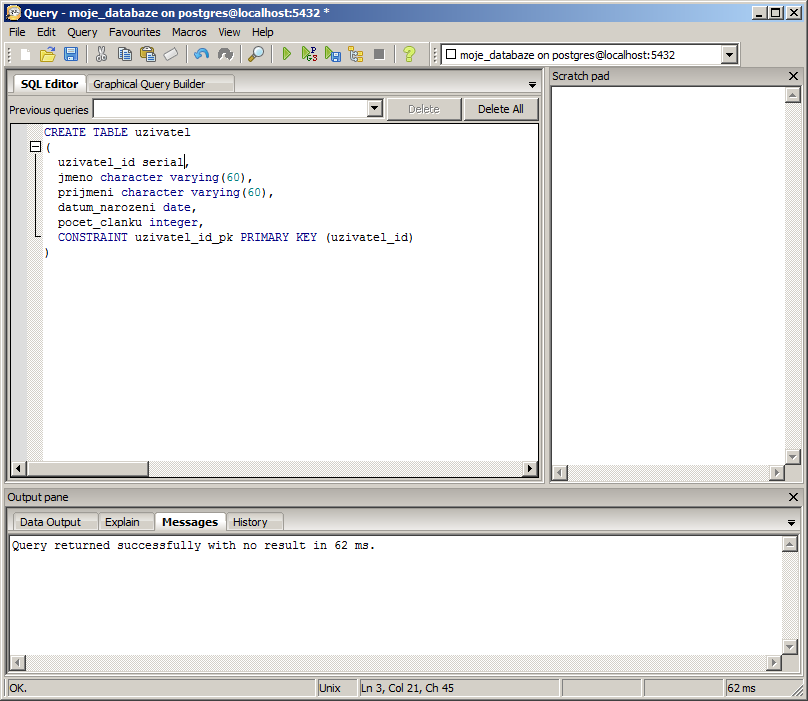
Příště si tabulku naplníme nějakými daty 
- Pro vkládání komentářů se musíte přihlásit